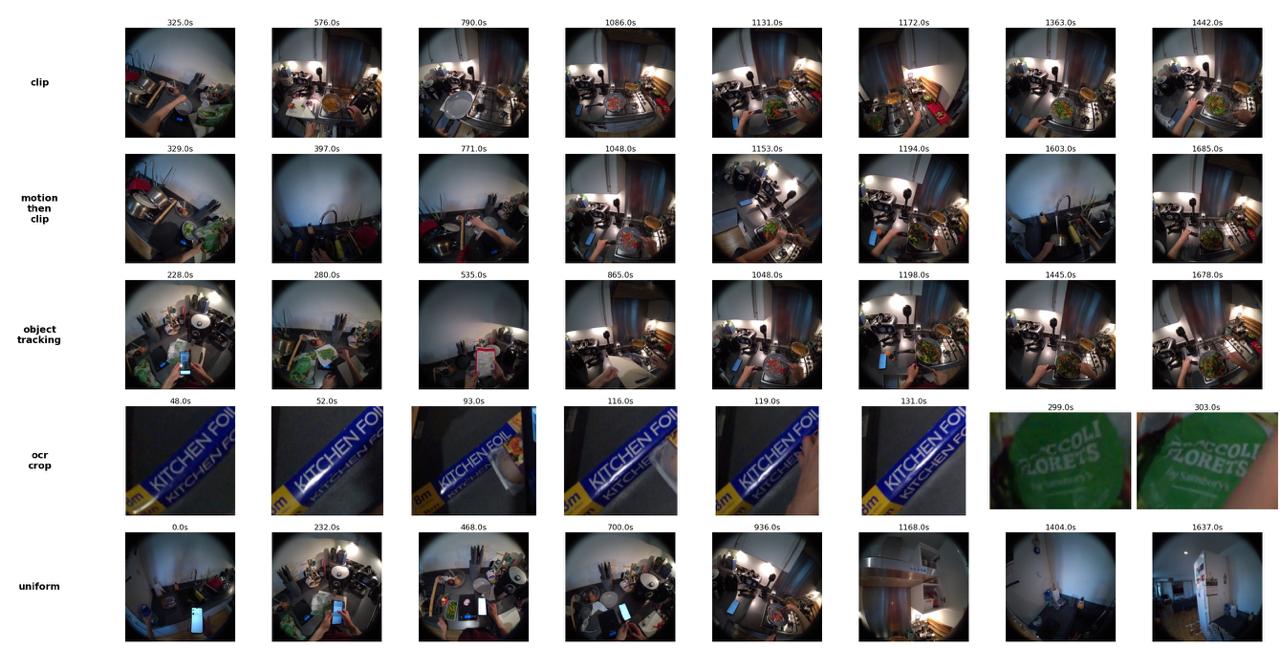
We study whether targeted auxiliary evidence can improve egocentric video QA under practical frame-budget and model-size constraints. Using HD-EPIC, a highly-detailed egocentric benchmark with 41 hours of video and 26K multiple-choice questions across 7 major categories, we compare a resource-bounded native-video baseline against six evidence tools: uniform frame sampling, CLIP retrieval (ViT-B/32), a Motion+CLIP cascade, OCR Crop, object tracking (GroundingDINO-tiny), and Uniform+CLIP.
We run a controlled ablation under a fixed budget of k=8 auxiliary frames, comparing augmentation (native video + auxiliary frames) against replacement (auxiliary frames only). On the 719-question fair intersection used for the mode comparison, the best augment tool (OCR Crop, 33.7%) barely edges the best replace tool (CLIP, 32.5%), both near the no-tool baseline of 32.3%. Replace mode, however, preserves a much larger per-question routing opportunity on this matched subset (+17.4 pp oracle gap vs. +6.1 pp for augment), making it cost-efficient at ~9× fewer frames.
Across 8 routing methods evaluated in replace mode, only a hand-crafted rule-based keyword router beats the best fixed tool (+3.9 pp), recovering the entire between-category gap. Learned classifiers fall below their matched single-tool baselines across the full, helpful, and cached-frame subsets. A large within-category gap of +16 pp to the perfect per-question oracle remains.
Long-form first-person video question answering is inherently an active-vision problem: not every moment in a video is equally informative, and the evidence needed to answer a question may be brief, local, or easy to miss. In practice, however, compute and memory constraints often prevent us from feeding every frame to a very large video model. We therefore study a resource-bounded setting with a frozen Qwen3-VL-2B model, sampling the native video at 1 FPS with a cap of 64 frames. For a 6.4-minute clip (384 s), this means one frame every ≈ 6 seconds, leaving large temporal gaps where brief events can be missed entirely. Important cues such as scale readings, ingredient labels, or brief object interactions can be easily missed.
Prior work addresses this by selecting or replacing parts of the visual input with targeted evidence. However, these approaches discard the global temporal context of the full video, which a modern video-native VLM already processes well. We instead study auxiliary evidence selection in two modes: augmentation (native video + auxiliary frames) and replacement (auxiliary frames only). We first compare both modes under the same budget, then use replacement — which preserves a 3× larger per-question routing opportunity — as the setting for our routing experiments.
This framing lets us ask three precise questions: (1) Can targeted auxiliary evidence improve egocentric video QA on top of the native video input of a modern VLM? (2) Is augmentation more effective than replacement under the same evidence budget? (3) If gains are category-specific, are they strong enough to justify question-type-conditioned tool routing?
We evaluate on HD-EPIC, a highly-detailed egocentric benchmark with 41 hours of kitchen video and 26K multiple-choice VQA questions across subcategories within all 7 major categories including Recipes, Ingredients, Object Motion, Nutrition, and 3D Perception. We focus on clips ≥ 6.4 minutes, where a limited native-frame budget leaves enough temporal sparsity that targeted frame selection may recover evidence missed by uniform video sampling.
Prior work on long-video understanding uses evidence selection exclusively in a replacement setting, where selected frames or segments become the model's only visual input. Our work differs in two key ways: we study both augmentation (native video + auxiliary frames) and replacement as complementary conditions — finding that replacement preserves more routing opportunity — and our final goal is a question-type-conditioned router introduced only if the ablation reveals systematic tool-specific gains.
Frame selection GroundVQA (Di & Xie, CVPR 2024) performs temporal grounding before QA on long egocentric videos, localising the relevant segment before passing it to the model — a replacement approach that discards global context. Q-Frame (Zhang et al., ICCV 2025) uses CLIP text-image similarity to dynamically select the most relevant frames for a given question, with multi-resolution adaptation. M-LLM Frame Selection (Hu et al., CVPR 2025) trains a lightweight multimodal selector to score frames before passing the best ones to a frozen downstream VLM. All three operate in replacement mode and apply a single fixed selection mechanism rather than routing between strategies by question type.
Tool-based retrieval and agents VideoAgent (Wang et al., ECCV 2024) uses a LLM as an agent that iteratively calls retrieval tools to assemble evidence, reasoning only over tool outputs without ever passing the full video to the VLM. Video-RAG (Luo et al., NeurIPS 2025) uses open-source tools (OCR, ASR, object detection) to extract text-based auxiliary information alongside video frames. Neither considers question-type-conditioned routing.
Egocentric MFAS (Zhang et al., ICML 2024) performs adaptive patch-level selection for egocentric VQA, showing that zooming on local details improves recognition of small objects, directly motivating our OCR+crop tool. EgoTextVQA (Zhou et al., CVPR 2025) shows that even Gemini 1.5 Pro reaches only 33% accuracy on scene-text questions in egocentric video, motivating the use of specialized OCR evidence.
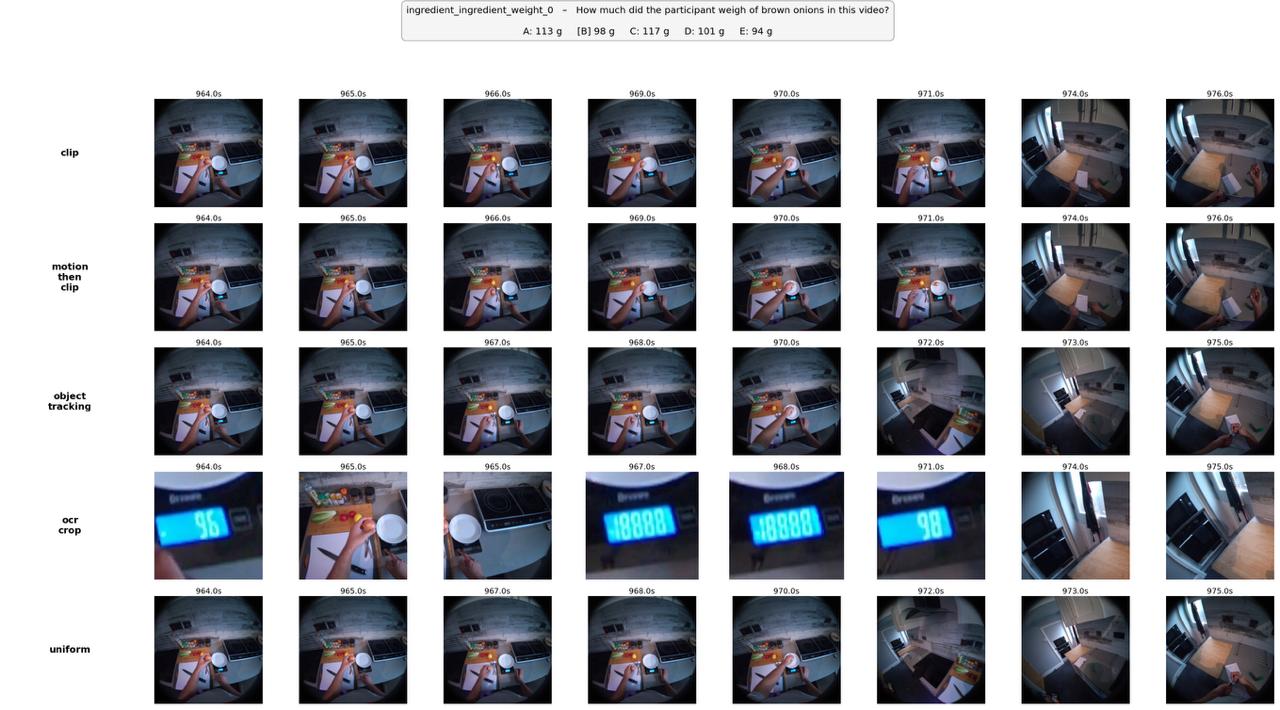
For each question-video pair from HD-EPIC, we sample a candidate frame pool at 1 FPS from the clip window. An auxiliary evidence tool selects k=8 frames from this pool (our default budget; we ablate over k ∈ {8, 16, 32} in Exp. 3). The frozen VLM (Qwen3-VL-2B) then receives either: (a) the native video + the k auxiliary frames (augment mode), or (b) only the k auxiliary frames (replace mode), along with the multiple-choice question.
Uniform
Selects k frames at evenly-spaced indices from the candidate pool. Provides temporal coverage with no question-specific bias. Used as the temporal baseline.
CLIP Retrieval (ViT-B/32)
Ranks candidate frames by text-image cosine similarity to the question using OpenAI CLIP (openai/clip-vit-base-patch32). Uses hierarchical score-based selection to ensure temporal diversity within the top-k.
Motion + CLIP (cascade)
Two-stage cascade: motion detection (L1 pixel diff) over-selects 3× budget at high-change moments, then CLIP refines to the most question-relevant k frames.
OCR Crop
EasyOCR ranks frames by detected-text confidence; saliency-based crop refinement then extracts high-resolution patches (≥384 px) around text regions and salient areas.
Object Tracking (GroundingDINO-tiny)
Zero-shot object detection using IDEA-Research/grounding-dino-tiny. Extracts the object name from the question, scores frames by max detection confidence, and selects the k most salient frames.
Uniform + CLIP (cascade)
Combines uniform temporal coverage (stage 1) with CLIP semantic retrieval (stage 2). Ensures both temporal spread and question relevance within the k-frame budget.
We evaluate on HD-EPIC questions filtered to clips ≥ 6.4 minutes (min_clip_duration_s=384), excluding TIME-tagged and multi-video questions. This yields 1,035 questions across 10 categories. For augment/replace head-to-head comparisons we further restrict to the fair intersection of 719 questions where all 6 tools produce a result in both modes. Each condition is run in both augment (native video + k aux frames) and replace (k aux frames only) mode. The metric is 5-choice multiple-choice accuracy.
In Stage 2, we test 8 routing strategies in replace mode (k=8): (1) category-level LOOCV, (2–3) TF-IDF bigrams with LogReg/kNN, (4) a rule-based keyword router (regex over question text), (5) tool-agreement ensemble majority vote, (6) CLIP text embeddings (ViT-B/32) with LogReg/kNN, (7) 11 visual features per question (motion energy, motion std, brightness, contrast, colorfulness, edge density, clip length, CLIP text-image similarity mean/max/std, OCR density) with LogReg/kNN, and (8) combined text+visual features. Methods 1–6 are evaluated with leave-one-category-out cross-validation (LOOCV) on all 1,035 questions and, where applicable, with 80/20 splits on the 700 helpful-category questions. Visual methods require cached frames, so Methods 7–8 use the visual subset (623 questions for LOOCV; 427 helpful-category questions for 80/20). Each learned method is tested with both Logistic Regression and k-NN (k=5).
We run four experiments on HD-EPIC, each addressing one of our three research questions. The frozen VLM is Qwen3-VL-2B-Instruct throughout. All experiments use a default budget of k=8 auxiliary frames drawn from a 1 FPS candidate pool. The evaluation set covers 1,035 questions from 10 long-video categories (clips ≥ 6.4 min). For head-to-head augment/replace comparisons we use the fair intersection of 719 questions where all 6 tools are available in both modes.
Two reference points appear throughout: random chance = 20% (5-choice MCQ); and the perfect oracle, a theoretical upper bound computed by assigning each question the tool that answers it correctly. It cannot be deployed in practice but measures how much a router could gain if it made no mistakes.
Each panel shows k=8 frames selected by two strategies for the same question.
qwen_native serves as the reference. Evaluated on 719 fair-intersection questions.Figure 1. On the 719-question fair intersection, best-tool accuracy is near-equal across modes (augment 33.7% vs. replace 32.5%), but the oracle gap is nearly 3× larger in replace mode (+17.4 pp vs. +6.1 pp). Dashed line = qwen_native baseline (32.3%).
The two modes are nearly tied on best-tool accuracy (33.7% augment vs. 32.5% replace, +1.1 pp). The oracle bars tell a different story on the same 719 questions: replace preserves far more per-question routing opportunity (49.9% oracle vs. 39.8%). Adding the native video compresses the oracle gap by ~65%, because all tools converge once the VLM already has global context.
Figure 2. Routing opportunity decomposition on the full replace-mode routing set (k=8, n=1,035). This is larger than the 719-question fair intersection used in Figure 1. The +19.9 pp total gap splits into +3.9 pp between categories (fully recovered by the rule-based router) and +16.0 pp within categories (unsolved by any method).
This larger replace-mode routing gap is interesting because replace uses far fewer frames than augment. One possible explanation is that auxiliary frames in augment mode are appended after the native video, which may make them harder for the model to integrate or may even distract it from the original temporal context. In replace mode, the model is forced to rely on the selected evidence frames, so each tool's inductive bias remains clearer and the difference between tools is easier to exploit.
On the full replace-mode set, the total routing potential (+19.9 pp) can be decomposed into two distinct gaps. The between-category gap (+3.9 pp) exists because the best tool differs across question categories. A router that simply knows the category and assigns its historically best tool recovers this gap entirely. The within-category gap (+16.0 pp) is harder: even within a single category, different questions benefit from different tools, and no method we tested can exploit this signal. This decomposition explains why Exp. 4 focuses on category-level routing first.
uniform, clip, motion_then_clip, ocr_crop, object_tracking, and uniform+clip, against the native baseline on the 719-question fair intersection, breaking results down by overall accuracy and by each of the 10 HD-EPIC categories.Figure 3. Per-tool accuracy in augment (dark) vs. replace (grey) modes (k=8, n=719). OCR Crop is the only tool with a large augment advantage (+3.5 pp). CLIP, Motion+CLIP, and Uniform+CLIP score higher in replace mode, showing augment is not uniformly better. Dashed red line = qwen_native (32.3%).
Augment does not uniformly outperform replace. CLIP, Motion+CLIP, and Uniform+CLIP each score higher in replace mode. OCR Crop is the only tool with a large augment advantage (+3.5 pp), because text/detail crops are complementary to the native video rather than redundant with it.
| Category | n | qwen_native | Best aug. tool | Aug. best | Δ vs native | Best rep. tool | Rep. best |
|---|---|---|---|---|---|---|---|
| obj. motion count | 200 | 44.5% | ocr_crop | 49.0% | +4.5pp | uniform | 50.0% |
| obj. motion itin. | 134 | 11.2% | motion_then_clip | 14.2% | +3.0pp | ocr_crop | 17.9% |
| 3d perc. fixture | 86 | 25.6% | object_tracking | 26.7% | +1.2pp | ocr_crop | 32.6% |
| recipe multi-step | 50 | 32.0% | uniform+clip | 34.0% | +2.0pp | clip | 30.0% |
| recipe multi-recog. | 50 | 56.0% | clip | 58.0% | +2.0pp | uniform+clip | 54.0% |
| ingredient order | 50 | 34.0% | motion_then_clip | 36.0% | +2.0pp | motion_then_clip | 32.0% |
| ingredient exact | 50 | 26.0% | ocr_crop | 28.0% | +2.0pp | ocr_crop | 16.0% |
| nutrition | 35 | 54.3% | uniform | 65.7% | +11.4pp | motion_then_clip | 57.1% |
| fine-grained act. | 31 | 25.8% | uniform | 25.8% | ±0.0pp | object_tracking | 35.5% |
| recipe step | 33 | 15.2% | uniform | 12.1% | −3.0pp | uniform+clip | 24.2% |
Table 2. Per-category breakdown (augment mode, k=8, n=719). For each category: native baseline, best augment tool with accuracy and Δ vs. native, and best replace tool for comparison.
In 8 of 10 categories, the per-category best augment tool beats qwen_native (1 tied, 1 below). Replace mode tends to produce higher best-tool scores in categories with high oracle headroom (e.g. fine-grained, recipe step), while augment dominates in nutrition and ingredient exact.
Figure 4. Heatmap: augment mode accuracy per tool per category (k=8, n=719). Color scale is normalized per row (white = row minimum, red = row maximum). ★ marks the best tool per category. All six tools win at least one augment category, confirming that no single evidence strategy is universally optimal.
Reading the heatmap by row: rows where all cells have similar brightness (e.g. recipe recog.) indicate that all tools perform equally, so no routing gain is possible. Rows with high contrast (e.g. nutrition, ingredient exact) signal that the right tool matters a lot. The ★ column shifts across rows, with no fixed winner across categories.
Figure 5. Accuracy vs. frame budget in augment mode (obj. motion count, n=200). CLIP, Motion+CLIP, Object Tracking, and Uniform+CLIP collapse at k=32 due to resolution compression when 32 aux frames compete with the native video for context budget. OCR Crop is the most robust (−4.5 pp from k=8 to k=32); Uniform declines moderately (−11 pp).
At k=32 in augment mode, CLIP-based and tracking tools collapse catastrophically (−25 to −35 pp). When 32 aux frames are added alongside the native video, Qwen3-VL must fit all frames into a fixed context window. Each frame is allocated fewer tokens, reducing its effective resolution. Tools that rely on fine-grained image features (CLIP similarity, GroundingDINO detections) degrade severely at low resolution. This collapse does not appear in replace mode, where no native video competes for the context budget.
Figure 6. The 8 routing methods grouped by input signal. Each row shows the feature representation (bar charts = feature vectors, sparse = TF-IDF, dense = CLIP, coloured bars = 11 visual descriptors) and the classifier used. M4 (red, ★) marks the only method that beats its matched baseline; M1, M4, and M5 require no learned classifier. Tool colour dots in M1 indicate per-category tool assignment. † Visual methods require cached candidate frames (~60% of questions).
Figure 7. LOOCV routing results in replace mode. Methods without † use all categories (n=1,035; best single tool = 32.0%; oracle = 51.9%). Visual methods require cached frames and use the visual subset (n=623; matched best single tool = 33.7%; oracle = 52.5%). Only the rule-based router beats its matched best-single-tool baseline.
Helpful categories 80/20 (n=700)
Matched baseline: motion_then_clip at 38.3%.
Rule-based routing reaches 42.7% (+4.4 pp).
TF-IDF and CLIP-text classifiers cluster at 35.7%, so learned text routing remains below the fixed-tool baseline even in the easier within-distribution split.
Visual + helpful 80/20 (n=427)
Matched baseline: motion_then_clip at 41.9%.
Visual and text+visual routers reach at most 39.6% (−2.4 pp).
The bonus text-only kNN run comes closest at 41.7% ± 4.1, but still does not exceed its matched baseline.
Results across 8 routing methods: (1) The rule-based router reaches 35.9% LOOCV and 42.7% on helpful-category 80/20. (2) TF-IDF bigrams and CLIP text classifiers both cluster at ~31–32% LOOCV. (3) On the cached-frame subset, visual feature classifiers peak at 31.0% LOOCV against a matched baseline of 33.7%. (4) Combined text+visual features perform no better than visual alone. (5) The text-only kNN run reaches 41.7% on the visual+helpful 80/20 subset, the strongest learned result but 0.3 pp below its matched baseline.
Our main answer is nuanced. Targeted auxiliary evidence can help egocentric video QA, but not as a universal add-on to the native video input. Under our resource-bounded setup, the best augment tool improves only slightly over the native-video baseline (33.7% vs. 32.3%), so simply appending selected frames is not enough to produce a large overall gain. The stronger signal is conditional: different question types benefit from different evidence tools, especially for cues such as scale readings, ingredient labels, object motion, and temporal localization.
This leads to two conclusions about routing. First, augment and replace modes are nearly tied on best-tool accuracy on the 719-question fair intersection (+1.1 pp), but replace mode preserves a much larger routing opportunity on that matched subset (+17.4 pp oracle gap vs. +6.1 pp), making it the better setting for studying tool choice. Second, routing is useful only when it captures real question-type structure: on the full 1,035-question replace-mode routing set, a hand-crafted rule-based router is the only method that beats the best fixed tool (+3.9 pp LOOCV; +4.4 pp on helpful-category 80/20), while learned text, visual, and combined classifiers all fall below their matched single-tool baselines. The remaining +16 pp within-category oracle gap shows that the main unsolved challenge is per-question routing, which likely requires stronger visual or model-confidence signals beyond cheap first-order descriptors.
Sample size
Small per-category samples (as few as n=31) mean results lack statistical confidence for some categories.
Future work: Evaluating on the full HD-EPIC set (all clip lengths) would increase per-category n and yield more reliable category-level comparisons.
Within-category routing
The +16 pp within-category oracle gap is unsolved. Cheap visual features are insufficient; routing at the question level requires stronger signals.
Future work: Model confidence scores, VLM attention maps, or fine-grained embeddings (e.g. CLIP ViT-L/14) could provide the per-question discriminability that first-order descriptors lack.
Single domain
All experiments are conducted on long HD-EPIC kitchen videos. A short/medium-video check showed a smaller routing gap (+6.6 pp vs. +19.9 pp), so our conclusions are strongest for long-video QA.
Future work: Repeating the study on Ego4D or EPIC-Kitchens would test whether the between-category gap and tool rankings hold across different activity domains and clip lengths.
Cheap tools
Evidence tools use lightweight models (CLIP ViT-B/32, GroundingDINO-tiny, EasyOCR). Stronger backbones could change the relative tool ranking and routing conclusions.
Future work: Replacing CLIP ViT-B/32 with ViT-L/14 or using a larger OCR model (e.g. PaddleOCR) would test whether tool quality is the binding constraint.